Sandhog CS 175: Project in AI (in Minecraft)
Deep Q Pig Chase from Hector Flores on Vimeo.
Project Summary
The focus of our project is to design and implement a learning algorithm that trains an agent to collaborate with another (human or non-human) agent to catch a pig in Minecraft according to the rules of The Malmo Collaborative AI Challenge.
We have defined our baseline agent to be one that uses A* to determine the shortest distance to aid in capturing the pig. We aim to improve our baseline by using reinfocement learning and train an agent to maximize aggregate future rewards.
Given the complexity of the collaborative challenge, we will employ off-the-shelf deep learning and reinforcement learning libraries to provide the necessary flexibility to explore various reinforcement design paradigms along with parameter tuning.
Approach
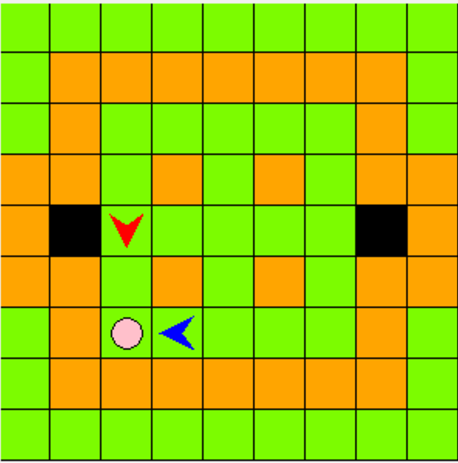
We consider the task in which our agent interacts with the Minecraft environment by making sequence of actions, observations, and receiving rewards. At each time step, the agent selects an action from the action space, . The agent observes an image from the emulator, which is a vector of pixel values representing the current screen frame. The agent also receives a reward representing the change in game score. Although the game score depends on the previous sequence of actions and observations, immediate rewards are described as:
- +5 for exiting through a gate
- +25 for catching the pig
- -1 for each action
A symbolic representation of the state space is shown in figure 1.
Since the agent only observes the current screen, it is impossible for the agent to fully perceive the current situation fom the the current screen . Therefore, we consider the sequences of actions and observations, , where is the vector of pixel values that represent the visual input from the agent. The sequences are large but finite, therefore formalizing our finite Markov Decision Process (MDP) where the sequence is a distinct state at each time .
The goal of our agent is to select actions in order to maximize future rewards. With the discount factor of , our future reward at time is defined as:
where is the number of time steps in an episode of the pig chase game. We use the standard definition of the optimal action-value function in which the maximum expected reward acheivable by following any policy , after seeing some sequence and taking some action is,
The optimal policy can be obtained by solving the Bellman equation iteratively, however we would have to maintain estimates of the action-value function for all states in a -table. Since our state are a vector of screen pixels that are rescaled to an image of size with consecutive images and gray levels, our -table would be .
To avoid an extremely large Q-table, we used a function approximator to approximate the function:
In this project we used a convolution neural network as a nonlinear function approximator to estimate the action-value function, where is our neural network weights.. The architecture for our neural network is as follows:
$$\begin{array}{|c|c|c|c|c|c|c|} \hline \textbf{Layer} & \textbf{Input} & \textbf{Filter size} & \textbf{Stride} & \textbf{Number of filters} & \textbf{Activation} & \textbf{Output} \\ \hline \text{Convolution 1} & 84\times84\times84 & 8\times8 & 4 & 32 & \text{ReLU} & 20\times20\times32 \\ \hline \text{Convolution 2} & 20\times20\times32 & 4\times4 & 2 & 64 & \text{ReLU} & 9\times9\times64 \\ \hline \text{Convolution 3} & 9\times9\times64 & 3\times3 & 1 & 64 & \text{ReLU} & 7\times7\times64 \\ \hline \text{Dense 4} & 7\times7\times64& & & 512& \text{ReLU} & 512\\ \hline \text{Dense 5} & 512& & & 3& \text{Linear} & 3\\ \hline \end{array}$$
The -learning update uses the Huber loss function, defined as:
where is the outlier threshold parameter. We used stochasitc gradient descen with a learning rate to optimize the Huber loss function.t
Since reinforcement learning with a neural network is known to be unstable we used experience replay
that randomly samples the data to remove correlations in the observation sequence. Our temporal memory
stores previouse samples of the agent’s experiences . During training,
we use a linear approach to offset the exploration/exploitation dilemma. The linear
approach linearly interpolates between to to linearly anneal as a function of the current episode.
Since we are working with raw pixel values for Minecraft, we introduce the function which takes most recent frames and scales the RGB frame into an grayscale frame
The learning algorithm can be described as the following:
- Initialize temporal memory to capacity
- Initialize action-value function with random weights
- Initialize target action-value function with weights
- For episode :
- Initialize sequence and preprocessed sequence
- For :
- Select random action with probability (linear anneal policy)
otherwise select - Execute action and observe reward and frame
- Set and preprocess
- .append()
- Sample random minibatch from
- Set
- Perform stocahstic gradient descent step on , where is the Huber loss function as previously described.
- Every steps reset
- Select random action with probability (linear anneal policy)
Evaluation
We chose five metrics to measure our agent performance over training time: mean value, actions per episode, maximum reward, minimum reward, and rewards per episode.
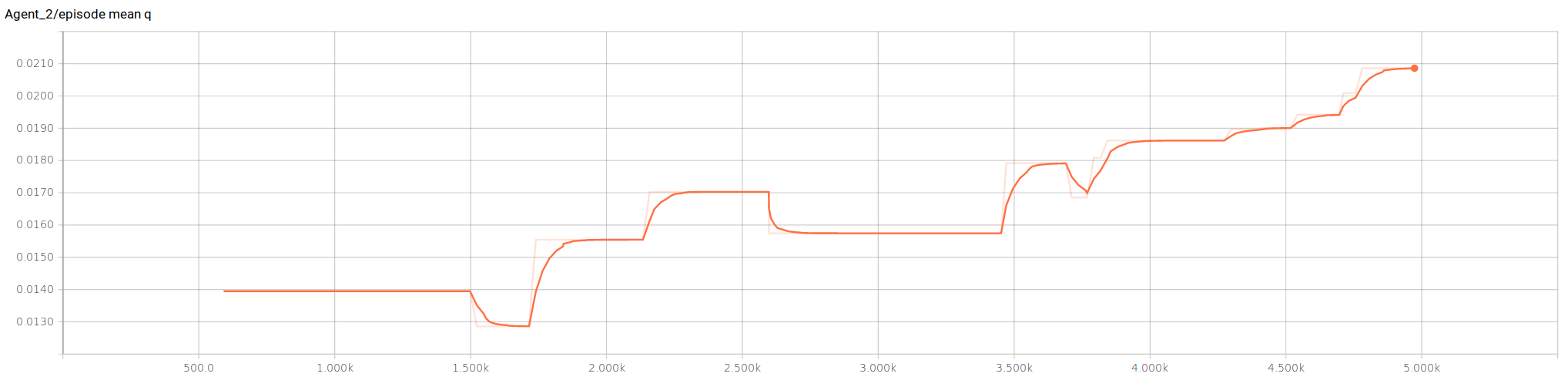
Figure 2 shows how our agent starts by choosing actions with low -values, and quickly begins to choose actions with a higher -value.
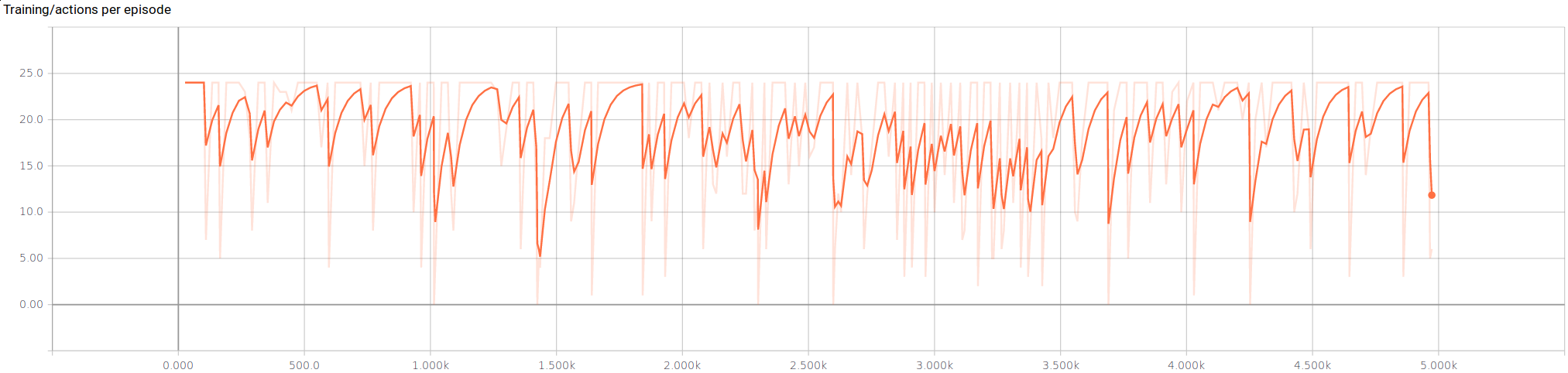
From figure 3, the number of actions per episode our agent makes is noisy at best. The variability seems to decrease after 2000 episodes, and with perhaps a longer training time it might stabalize to a smaller range of actions.
The maximum rewards during training is noisy, but averages around 6.
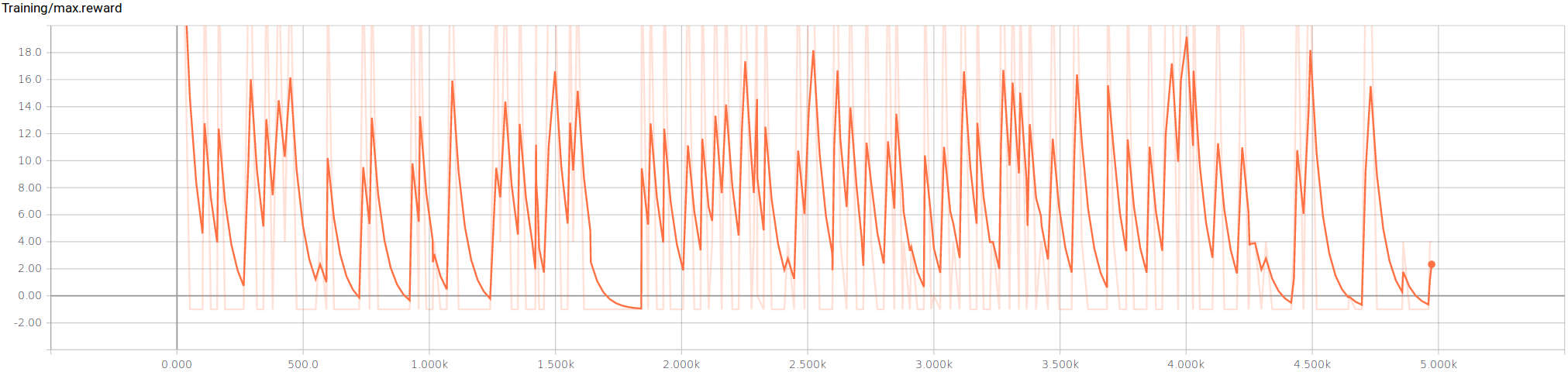
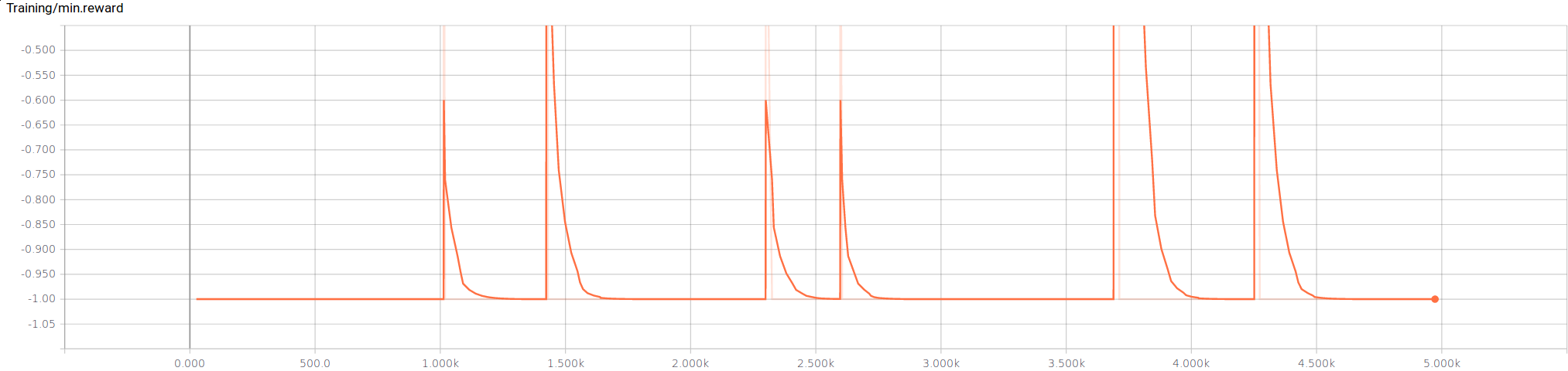
The minimum rewards during training has a periodicty where it’s peaks are grouped closely together.
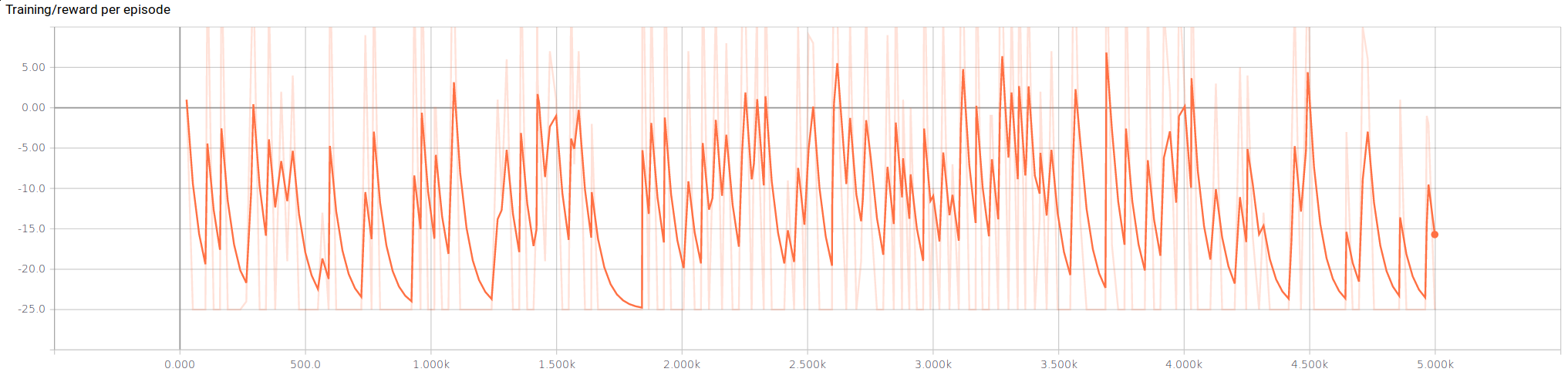
The total rewards per episode seem to average around zero. Our agent seems to break even in the pig chase challenge.
Remaining Goals and Challenges
Over the next few weeks, our goals are to:
- Experiement with other parameters and collect more data
- Increase the number of training epochs
- Run our model against the A* agent
The main challenge we face is having our agent to collaborate with an unknown agent. Since catching the pig is a joint effort, our agent has to be able to be able to determine what the other agent’s goals are.